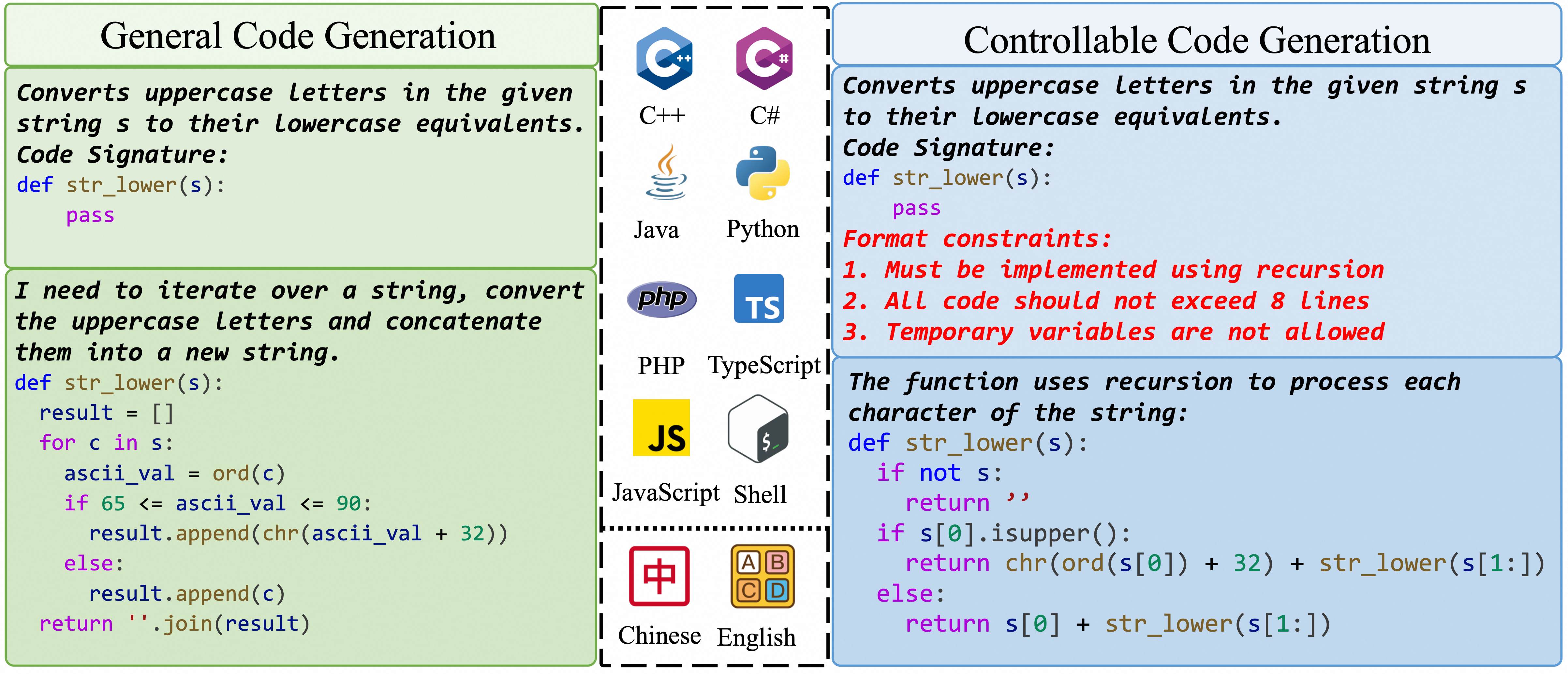
Code large language models (Code LLMs) have achieved significant advancements in various code-related tasks, particularly in code generation, where the code LLMs produce the target code from natural language descriptions. However, in realistic scenarios, users often expect the return code to strictly follow the given detailed requirements in many aspects (e.g. the style of code, the number of code lines, or the number of lines), instead of only requiring the correctness of the generated code. Controlled code generation means that the generated response from code LLMs should adhere to specific human guidelines or standards, whereas the LLM should have a strong instruction-following capability in the field of the code. In this paper, we propose forward constraints generation and backward constraints generation for controlled code generation to enhance the capability of LLM in following human instructions. Then, we build a multilingual benchmark IFEvalCode to evaluate the code instruction-following capability of the LLMs. IFEvalCode consists of 1.6K samples (Python, Java, Javascript, Typescript, Shell, Cpp, and C-sharp) and each test sample contains the Chinese and English query. Different from the existing code benchmarks, we separately design the test function to verify the correctness of the code (Corr.) and whether the generated code follows the human instruction (Instr.). Extensive experimental results on IFEvalCode of 40+ LLMs emphasize that closed-source LLMs still dominate in controllable code generation compared to open-source LLMs and the ability of LLMs to generate controllable code is far behind its ability to generate correct code
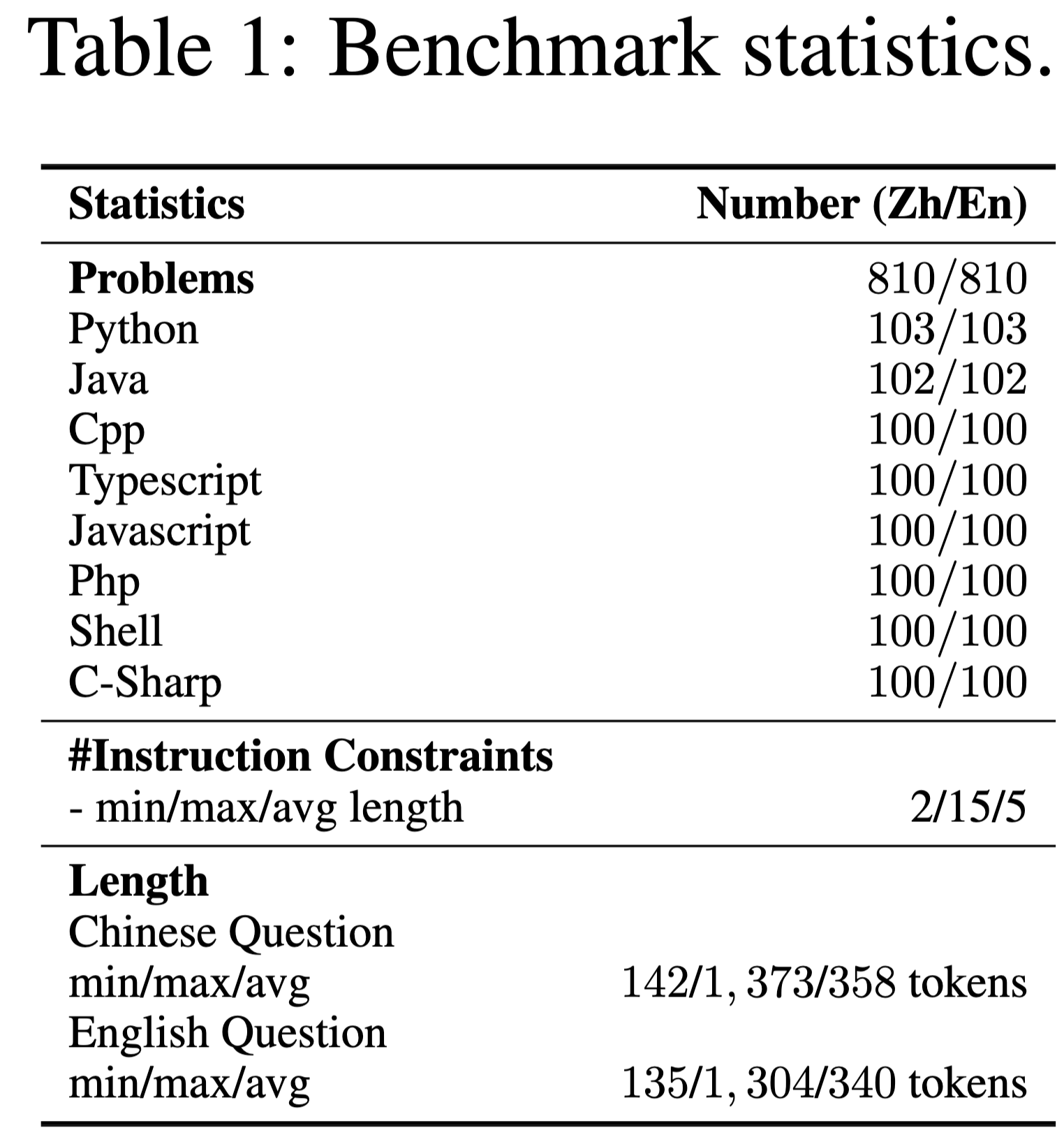
IFEvalCode consists of 1.6K problems. Each sample in IFEvalCode includes (en_question, zh_question, check_instruction, check_correctness), where `check_instruction` is used to check the code correctness and `check_correctness` judges whether the generated code follows the human instruction. We calculate the length of the question using the Qwen2.5-Coder tokenizer and count the number of instruction constraints for each sample. Each question contains 3 constraints and 100 tokens on average, where each prompt contains a problem description and the corresponding function or class signature.
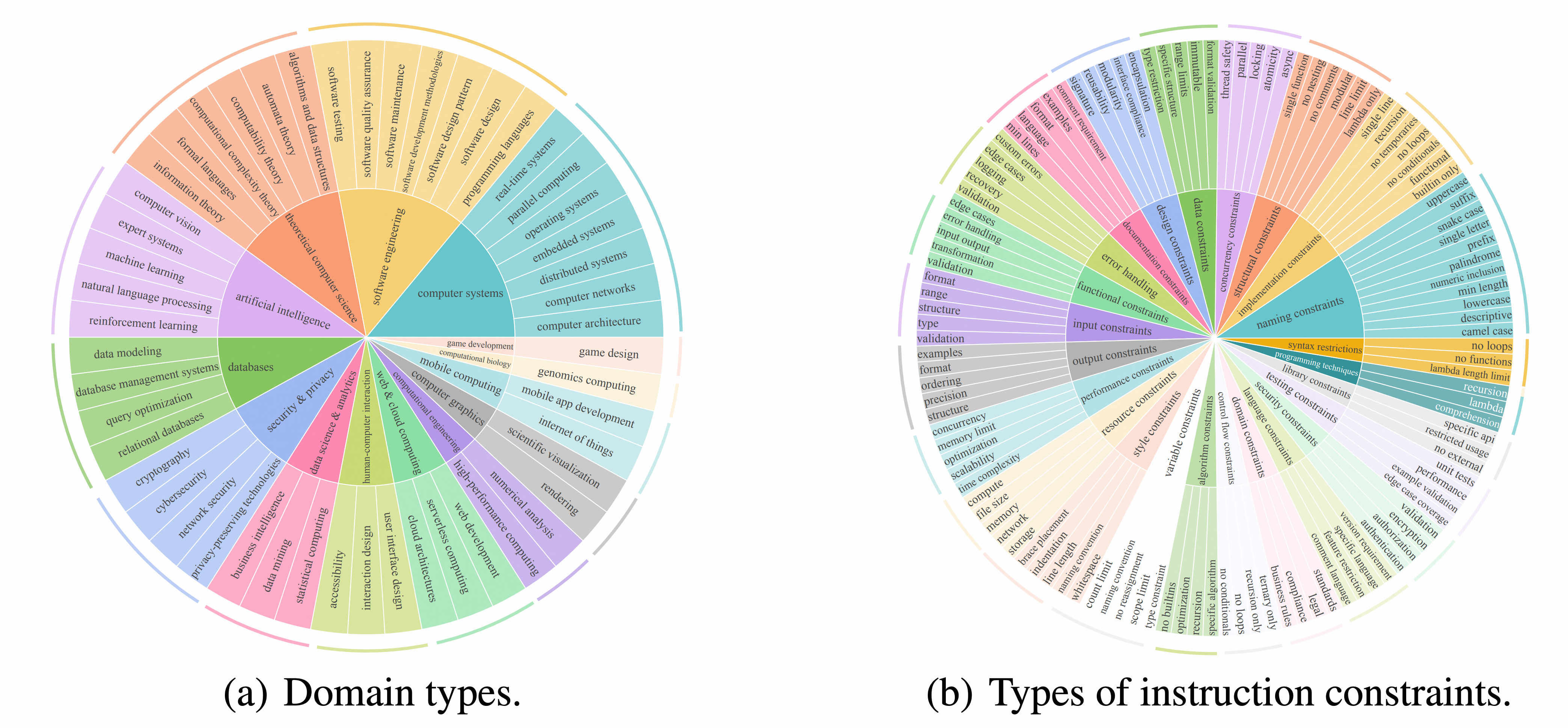
We show domain types and instruction types in IFEvalCode.

We show the examples of verifiable instruction with `check_instruction` in IFEvalCode.
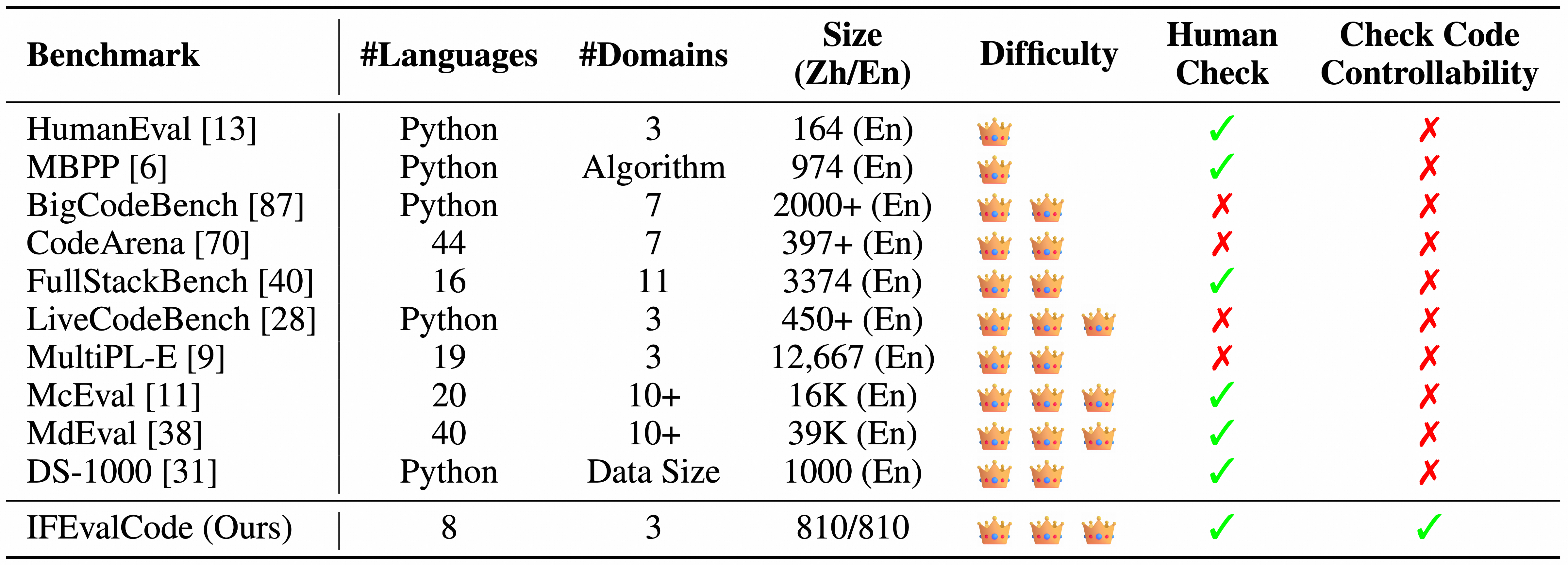
we compare IFEvalCode with other code evaluation benchmarks in 6 aspects. Considering the evaluation cost and effectiveness, IFEvalCode has 1620 samples for 8 programming languages and 2 human languages. Specially, we introduce the two part of unit tests to check the code correctness and whether the code follows the human instruction.
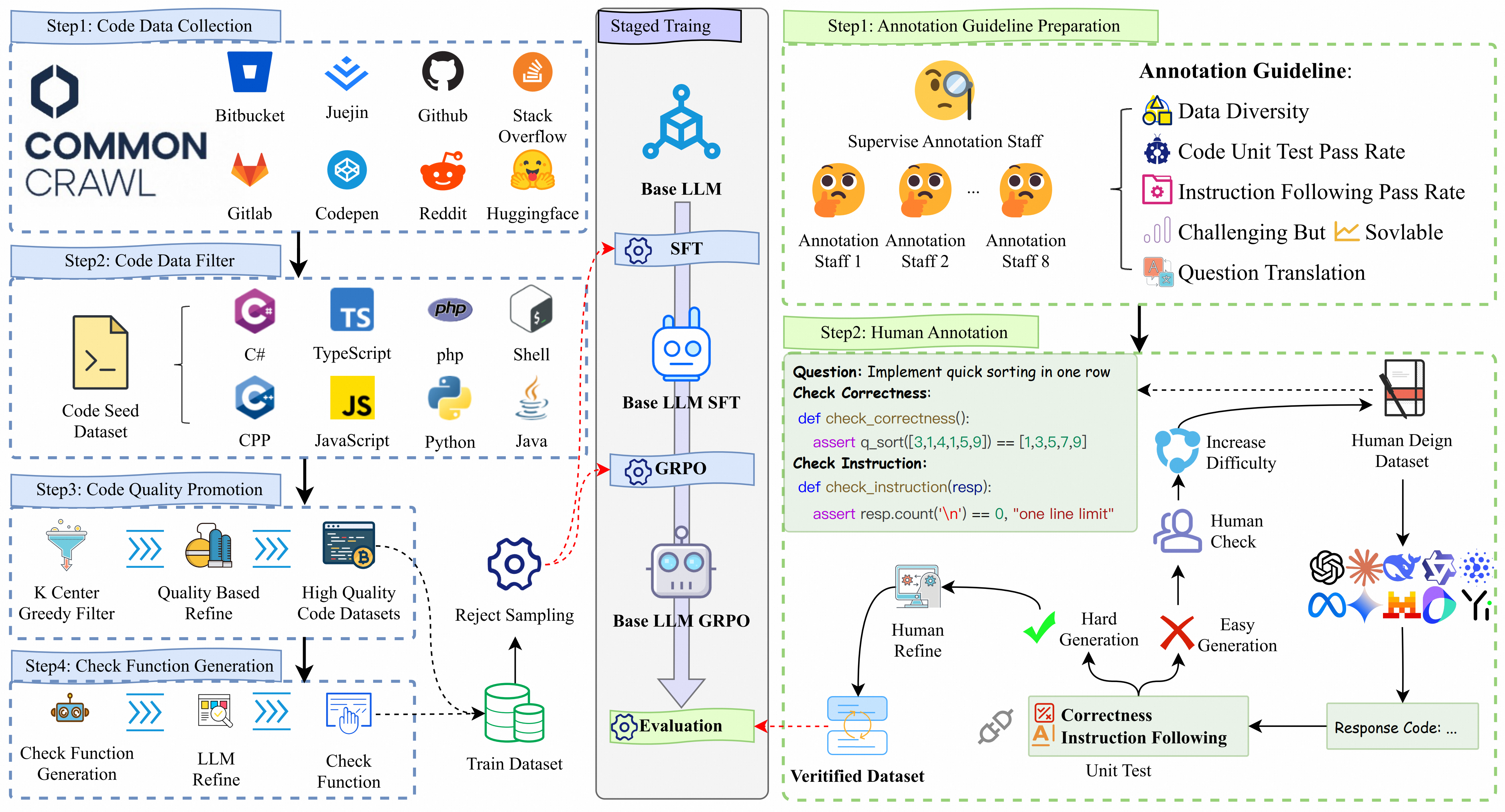
We begin by collecting code snippets and code-related documents from websites and recruit 6 computer science graduates as annotators. The annotators must follow the provided guidelines (1) ensure the diversity of the questions. (2) the question and instruction constraints should be challenging for existing LLMs. (3) translate the English question into the Chinese question. To increase the difficulty of IFEvalCode, the annotator filter out the questions, which half LLMs (GPT4o, DeepSeek-V3, Claude3.7, etc) can correctly answer.
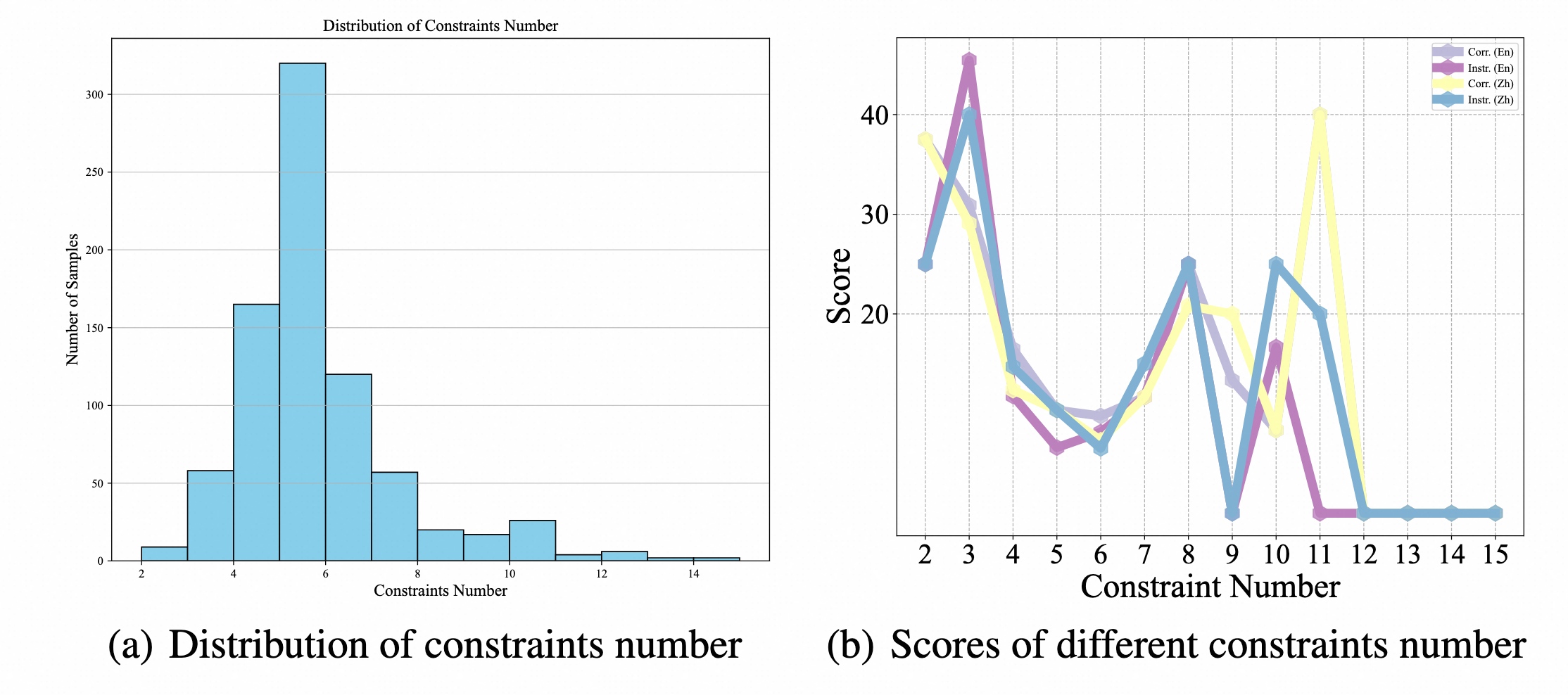
We plot the trends with the number of constraints increasing.
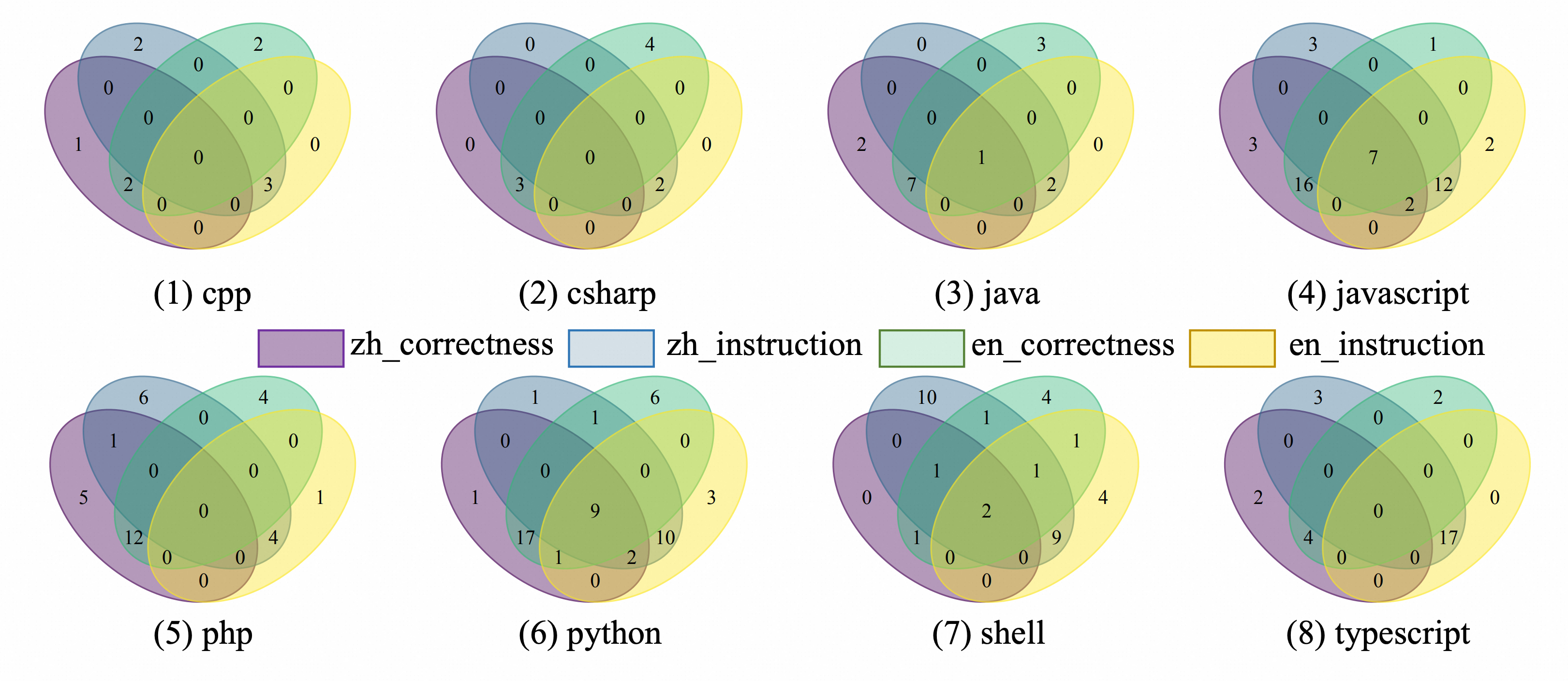
We show a grid of four-set Venn diagrams—one subplot per programming language—where each diagram partitions the model’s outputs into the following four evaluation sets: (1) Chinese‐prompt correctness, (2) Chinese‐prompt instruction compliance, (3) English‐prompt correctness, and (4) English‐prompt instruction compliance. By inspecting the overlaps, we can immediately see several consistent patterns across all eight languages: Correctness dominates. Both the Chinese‐correctness and English‐correctness sets are substantially larger than their corresponding instruction‐compliance sets, indicating that LLMs more often produce functionally correct code than code that also respects the extra constraints. Cross-language consistency in correctness. The overlap between Chinese‐correctness and English‐correctness is very large in every language, showing that whether the prompt is given in Chinese or English has little effect on a model’s ability to generate a passing solution. Instruction compliance is more fragile. The Chinese‐instruction and English‐instruction sets are much smaller, and their overlap is modest. In other words, even if a model is correct in both languages, it frequently fails to satisfy the same set of style or structural constraints when the prompt language switches. The smallest region is the four-way intersection. Only a small fraction of examples are simultaneously correct and compliant in both Chinese and English, demonstrating that achieving full controlled generation across languages remains the hardest challenge.